
Why Your Password Might Be in the Charts

Michael Brown
A Musical Approach to Cracking Passwords - Part 1
Penetration Testing
9 January 2026
In Brief
As user behaviour and passwords evolve so must our approach to cracking them. At Wilbourne we are constantly updating our methodologies and techniques and constantly developing new and novel approaches to changes in user behaviours and updates to technologies. This blog series walks through an example approach to cracking passwords.
Introduction
When performing penetration tests and red team engagements, it’s common to come across hashed passwords, often gathered through the exploitation of computer systems or network-based coercion attacks. Hash cracking involves guessing the original plaintext password, hashing it using the same algorithm and seeing if they match. Traditionally we use a list of common passwords and educated guesses (e.g. CompanyName123!) along with mangling rules to generate more permutations and increase the likelihood of a match (e.g. appending numbers to the end or replacing the letter O with the number zero).
As general security awareness and industry recommendations have evolved over the past decade (See NCSC, CISA and FBI guidance), users have been encouraged to move away from using traditional 8-12 character passwords to longer and stronger passphrases consisting of 3-6 randomly chosen (or generated) words, making them theoretically much more difficult for an attacker to guess or crack. In practice, it is still common for users to set passphrases to predictable values such as memorable quotes or phrases.
As user behaviour/passwords evolve so must our approach to cracking them. At Wilbourne we are constantly updating our methodologies and techniques and constantly developing new and novel approaches to changes in user behaviours and updates to technologies. This blog series walks through an example approach to cracking passwords.
Background

Chris Moberly's passphrase cracking wordlist acts as a jumping off point for passphrase cracking efforts, he has compiled a 459MB wordlist from phrases collected from a variety of sources including song lyrics from a list of popular artists. We felt that this was a limited view of musical genres and artists, as Moberly states that it is based a Rolling Stone article of the “100 Greatest Artists”, which seems to have last been updated in 2011. Cursory searches of iconic and memorable lyrics return no results and we felt there was an opportunity for a more comprehensive and contemporary list of song lyrics that could be iterated on and improved with time.
Moberly provides tools and documentation used to create and update the list. The script lyricpass.py takes artist names as arguments and scrapes lyrics from a website. This approach searches for lyrics by given artists rather than popular songs, this has the consequence of missing popular songs from artists who aren't themselves well known or considered “one-hit-wonders”. We will aim to improve on this approach by broadening the scope and refining the methodology of gathering and processing song lyrics for use in passphrase cracking.
Method
Version 1 of the song lyrics wordlist (lyricsv1.txt) was a rough proof of concept to see how feasible and effective a list like this could be.
When constructing more traditional wordlists like that of sports teams, locations or names of video games, existing datasets are used rather than actively scraping web pages. These datasets are designed for data analytics and usually include additional information that can be used to filter unneeded results or sort by popularity metrics like ratings.
The source we chose to use was 960K Spotify Songs With Lyrics data by BwandoWando, this data was gathered from Spotify's API. This dataset was one of the most comprehensive that we found without querying the API ourselves, which may be an option for a future version of this wordlist.
Throughout the process we used the csvkit suite of tools to avoid issues with commas, line feeds and quotation marks appearing in lyrical content, this would have caused issues with simple utilities like cut.
Throughout the process we used the csvkit suite of tools to avoid issues with commas, line feeds and quotation marks appearing in lyrical content, this would have caused issues with simple utilities like cut.
csvcut -d "," -q '"' -b -u1 -c lyrics songs_with_attributes_and_lyrics.csv > lyricsv1a.txt
We removed trailing and leading whitespaces, as well as quotes and duplicate lines.
sed -i 's/^\"//;s/\"$//;s/^\s*//;s/\s*$//' lyricsv1a.txt
sort -u lyricsv1a.txt > lyricsv1.txt
The resulting wordlist (lyricsv1.txt) was 18,975,568 lines long at 655 MB.
To benchmark each version of the wordlist, we ran them each against a static collection of hashes, comprised of official Hashmob “lefts”, lists of uncracked hashes from public data breaches. These hashes are part of a community hash cracking effort, meaning any results have not been previously found by the thousands strong Hashmob community of hash cracking enthusiasts and professionals.
The cracking jobs were run using Hashcat with pure kernels, this is due the fact that optimised kernels have an upper limit on the length of password candidates, which many passphrases would exceed. The lyricsv1.txt wordlist was run through two passphrase rule lists authored by Chris Moberly, these are quite basic as they are intended to be run in combination on complex lists, modifying word separators, performing basic character substitution and appending common numbers such as recent years. The pot file was disabled and the same hashes were used throughout to accurately judge the hit rate of each version of the wordlist.
Example Command:
.\hashcat.exe -a0 -m<hashtype> --potfile-disable .\hashes\hashmob\official\hashmob.net_official.<hashtype>.left .\wordlists\lyricsv1.txt -r .\rules\passphrase-rule1.rule -r .\rules\passphrase-rule2.rule
Hash Type (Hashcat Mode) | MD5 (0) | SHA1 (100) | NTLM (1000) | SHA2-512 (1400) | md5(md5($pass)) (2600) |
|---|---|---|---|---|---|
lyricsv1.txt Cracked | 7 | 3 | 3 | 2 | 2 |
Results
The results of the first batch of password cracking were encouraging, they showed a small number of hashes were cracked using just the proof of concept passphrase list and publicly available rules.
There are a number of refinements that can be made to our wordlist to provide us with more effective and efficient password cracking, but these results have demonstrated that previously uncracked hashes were cracked using this method.
These results provide the basis for which further analysis and additional testing will be performed to crack even more hashes.
Potential Improvements - Next Steps
During the initial testing of the lyricsv1.txt wordlist, several limitations were identified that can be improved in the future.
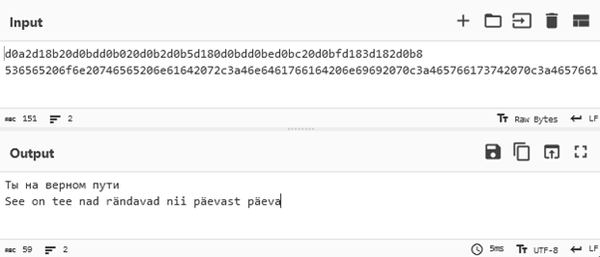
Figure 1 - Two hex encoded passwords returned by Hashcat with correct text encoding applied
1
Some of the identified passwords featured unusual characters, when UTF8 encoded they featured Cyrillic script and characters with diacritical marks. While this was beneficial for a list of hashes not tied to any particular country or culture, filtering the initial dataset based on language and regional popularity of songs could lead to a more efficient list that could be used with more complex rules.
2
Due to the lack of standardisation and minimal processing on the initial dataset, there were instances where phrases are overly long or fragmented in places that would not likely be considered for passphrases.

Figure 2 - The highlighted line is 308 characters long, unlikely to be used for a passphrase
To remove duplicates, version 1 of the wordlist has been sorted in alphabetical order. When cracking stronger hashes such as DCC2 (Domain Cached Credentials), it would be beneficial to sort the lines by popularity of song, so that more likely matches are prioritised.

Figure 3 - The highlighted line seems to have fragmented in the middle of a phrase, unlikely to be used for a passphrase
Additional analysis and processing could be used to break long lines into shorter phrases, and combining shorter phrases into singular lines, increasing the likelihood of finding a match.
For example, “Whisper words of wisdom, let it be” could be fragmented in three ways: “Whisper words of wisdom, let it be”, “Whisper words of wisdom” and “let it be”.
3
Looking Ahead
The next blog in this series will look to see how this approach can be improved with different methodologies and tools, with the goal of finding more effective ways to modify large data sets to crack predictable passphrases in an efficient manner.
If you would like to learn more or need assistance with performing penetration testing or red team engagements, please do not hesitate to get in touch with us.